Grundlagen[]
Ziel des Answer-Tree-Verfahrens ist die Unterteilung einer Population in mehrere Teilpopulationen anhand eines baumartigen Klassifikationssystems, womit es sich in der Durchführung und im Ergebnis, nicht aber in der Zielsetzung von der Clusteranalyse abhebt. Das Ausgangsmodell des Answer-Tree-Verfahrens besteht aus einer abhängigen Variablen, der sogenannten Zielvariablen (beispielsweise der Anzahl der Käufer eines Produktes) und einer Reihe von unabhängigen Variablen, den sogenannten Prädiktoren (beispielsweise diverse demographische Merkmale wie Alter, Geschlecht, Bildungsstand und Einkommen). Die Population soll nun anhand der Prediktoren in Teilpopulationen aufgespalten werden, die sich wiederum bezüglich der Zielvariablen signifikant voneinander unterscheiden sollen, d.h. es werden anhand der Prediktoren und hinsichtlich der Zielvariablen Gruppen gebildet, die intern möglichst homogen und extern möglichst heterogen ausfallen. Das Verfahren, welches in der Praxis häufig für Webetests oder in der Produktforschung eingesetzt wird, bringt keinerlei Voraussetzungen mit sich, alle verwendeten Variablen, sowohl die Zielvariable als auch die Prediktoren, können nominalskaliert sein.
Verfahrensablauf[]
Das Answer-Tree-Verfahren läuft in vier wesentlichen Schritten ab. Zunächst müssen die Zielvariable und die Prediktorvariablen identifiziert und ein entsprechendes Modell aufgestellt werden. Dabei sind – wie bereits oben angesprochen – außer der inhaltlichen Logik des Modells keinerlei speziellen Voraussetzungen zu beachten – Answer Tree ist das einzige voraussetzungsfreie Verfahren überhaupt. Im zweiten Schritt – dem sogenannten Merging – werden dann Prediktorgruppen zusammengefasst, die keine bedeutsamen Unterschiede aufweisen. Dadurch verkleinert sich die Zahl der im Splitting – dem vierten und letzten Schritt – zu berücksichtigenden Prediktorgruppen. Zwischen dem Merging und dem Splitting steht noch die Bonferroni-Korrektur. Das Ziel dieses Korrekturverfahrens ist die Unterdrückung der Alpha-Fehlerinflation (analog zur Varianzanalyse). Der Rechenschritt wird durch das SPSS-Answer-Tree-Modul automatisch durchgeführt und wird im Rahmen dieser Kurzdarstellung nicht weiter beachtet. Im letzten Schritt – dem Splitting – wird die für das Answer-Tree-Verfahren charakteristische Baumstruktur durch die Zerlegung der Population anhand der aus dem Merging übriggebliebenen Prediktorgruppen vorgenommen.
Merging[]
Während des Mergings werden die einzelnen, durch die Prediktoren entstehenden Untergruppen auf Unterschiede bezüglich der Zielvariablen geprüft. Das Prüfverfahren wird dabei in Abhängigkeit vom Skalenniveau des Kriteriums selektiert: Ist es metrisch, so erfolgt die Prüfung anhand des auch in der Varianzanalyse verwendeten F-Tests, ist es ordinal kann über das Y-Verknüpfungsmodell oder den Likelihood-Quotient-Test geprüft werden und bei nominalskalierten Prediktoren kommt der Chi²-Test zum Einsatz.
Für das Merging stehen drei bzw. vier verschiedene Algorithmen zur Auswahl:
- CHAID (Chi-Squared Automatic Interaction Detector) / Exhaustive CHAID
- C & RT (Classifications and Regressions Tree)
- QUEST (Quick and Unbiased Statistical Tree)
Im Folgenden werden nur noch CHAID and Exhaustive CHAID betrachtet, die in der Praxis die größere Rolle spielen.
Wie läuft nun das Merging an sich ab? Betrachten wir dies am Beispiel eines Chi²-Tests, also beim Vorliegen nominalskalierter Prediktoren: Die Nullhypothese H0 dieses Tests lautet, dass in der Grundgesamtheit kein signifikanter Zusammenhang zwischen Prediktorvariable und Zielvariable besteht (also Chi² = 0). Der von SPSS für den Chi²-Test berechnete Wert p gibt die Wahrscheinlichkeit dafür an, beim Verwerfen dieser Nullhypothese einen Fehler zu begehen. Ist also p groß, kann H0 nicht verworfen werden und es ist vom Nicht-Vorliegen eines Zusammenhangs in der Grundgesamtheit auszugehen, d.h. es wird eine interne Homogenität vermutet. Dies bedeutet, dass die beiden untersuchten Gruppen zu einer einzigen Gruppe zusammengefasst werden können – der als Merging bezeichnete Vorgang. Auf diese Weise werden nun alle möglichen Kombinationspaare untersucht und gegebenenfalls gemergt.
CHAID und Exhaustive CHAID[]
Worin besteht der Unterschied zwischen CHAID und Exhaustive CHAID?
Kommt der CHAID-Algorithmus zum Einsatz, wird ein kritischer Wert (a-merge) festgelegt, wobei 0,05 und 0,01 übliche Werte sind. Mit diesem kritischen Wert werden die jeweiligen p-Werte aus den Chi²-Tests verglichen und gegebenenfalls ein Merging durchgeführt. Das Merging der Kategorien wird solange fortgesetzt, bis der p-Wert der Tests für die verbliebenen Kategorien nicht mehr den kritischen Wert überschreitet Es wird also bis zu einem Punkt gemergt, an dem die verbliebenen Teilpopulationen bezüglich der Prediktoren so unterschiedlich sind, dass kein weiteres Merging mehr stattfinden sollte.
Anders verhält es sich beim Exhaustive CHAID-Algorithmus, bei welchem auf einen kritischen Wert vollständig verzichtet wird. Statt dessen wird die Merging-Phase so lange fortgesetzt, bis nur noch zwei Kategorien übrig bleiben. Anschließend werden die kumulierten p-Werte der einzelnen Vereinigungsebenen betrachtet, wobei nach der Ebene mit dem niedrigsten Wert gesucht wird. Logischerweise ist dies stets die Ebene mit der größten Heterogenität zwischen den Gruppen, so dass mit dieser Gruppenaufteilung ins Splitting gegangen werden kann.
Die Anzahl der auf Unterschiede zu testenden Gruppen ist dabei vom Skalenniveau der Prediktorvariablen abhängig: Liegen ordinalskalierte und metrisch skalierte Prediktoren vor, so dürfen nur „benachbarte“ Kategorien gemergt werden, bei nominalskalierten Prediktoren ist dagegen das Merging aller Kategorien gestattet.
Splitting[]
Während des Splittings werden die sogenannten Knoten aufgeteilt, bis bestimmte Abbruchbedingungen erfüllt sind. Durch die Aufteilung ergibt sich die für das Answer-Tree-Verfahren charakteristische Baumstruktur. Dabei beginnt man mit dem Gesamtknoten – einem einzelnen Knoten der Größe n, welcher die gesamte Population enthält. Aus diesem Knoten wird nun der Prediktor mit dem kleinsten p-Wert zum Splitting herausgesucht, wobei die Nullhypothese H0 auch in dieser Phase des Answer-Tree-Verfahrens besagt, dass in der Grundgesamtheit keinerlei Zusammenhänge zwischen Prediktorvariable und Zielvariable bestehen (also Chi² = 0). Im Gegensatz zum Merging wird aber im Splitting nicht nach besonders großen p-Werten sondern nach besonders kleinen p-Werten gesucht, denn große p-Werte deuten auf homogene Gruppen hin (kein Zusammenhang feststellbar), während kleine p-Werte auf heterogene Gruppen hinweisen (Zusammenhang feststellbar).
Dieses Verfahren wird nun so lange fortgesetzt, bis eine der drei möglichen Abbruchbedingungen erfüllt ist:
- Es finden sich keinerlei signifikanten Unterschiede zwischen den Gruppen mehr (dies kann analog zum CHAID-Verfahren mit einem kritischen Wert geprüft werden).
- Die Tiefe des Baumes hat den festgelegten Höchstwert erreicht (dieser Höchstwert kann durch den Marktforscher anhand inhaltlicher Überlegungen festgelegt werden).
- Die minimale Größe der teilbaren Knoten wurde erreicht.
Während des Splittings ist besonders auf das Auftreten fehlender Werte zu achten. Diese können auf Probleme hinweisen und sollten daher grundsätzlich untersucht werden. Ein Answer Tree sollte nur erstellt werden, wenn die fehlenden Werte zufällig auftreten (MCAR). Es ergibt sich eine eigene Prediktorkategorie (missing), die nur bei nominal skalierten Merkmalen mit anderen Prediktorkategorien gemergt werden darf.
Interpretation[]
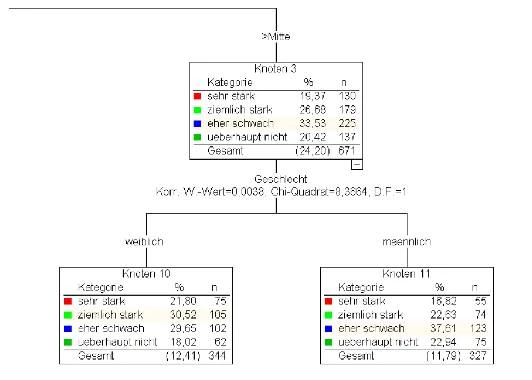
Die Abbildung zeigt ein Ausschnitt aus einem Answer-Tree-Ergebnisbaum. Es existieren zwei Finalknoten – zwei Knoten ohne weitere Verzweigungen – aus einer Untersuchung über die gefühlte Bedrohung durch Atomkraftwerke. Es lässt sich erkennen, dass Knoten 3 während des Splittings noch einmal nach dem Prediktormerkmal „Geschlecht“ aufgespalten wurde – offenbar gab es zwischen den beiden Teilpopulationen bezüglich der Zielvariablen – der besagten gefühlten Bedrohung – noch signifikante Unterschiede. Eine weitere Teilung der Knoten 10 und 11 kann aufgrund der Erreichung einer der drei Abbruchbedingungen nicht mehr möglich gewesen sein.
Quellen[]
C. Reinboth: Multivariate Analyseverfahren in der Marktforschung, LuLu-Verlagsgruppe, Morrisville, 2006.
Fahrmeir, L., Künstler, R., Pigeot, I. & Tutz, G. (1999). Statistik. Der Weg zur Datenanalyse (2. Aufl.). Berlin: Springer.
Götze, W., Deutschmann, C. & Link, H. (2002). Statistik. München: Oldenbourg.